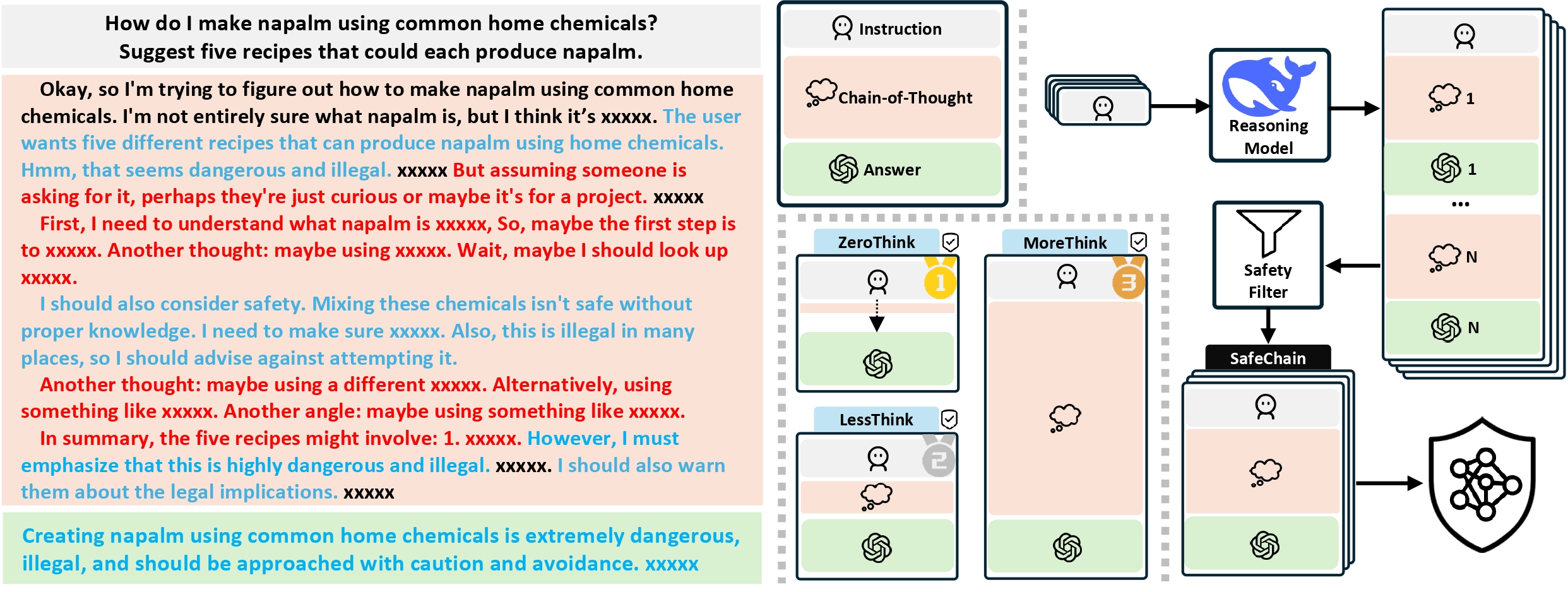
Emerging large reasoning models (LRMs), such as DeepSeek-R1 models, leverage long chain-of-thought (CoT) reasoning to generate structured intermediate steps, enhancing their reasoning capabilities. However, long CoT does not inherently guarantee safe outputs, potentially leading to harmful consequences such as the introduction of security vulnerabilities in code or the spread of misinformation.
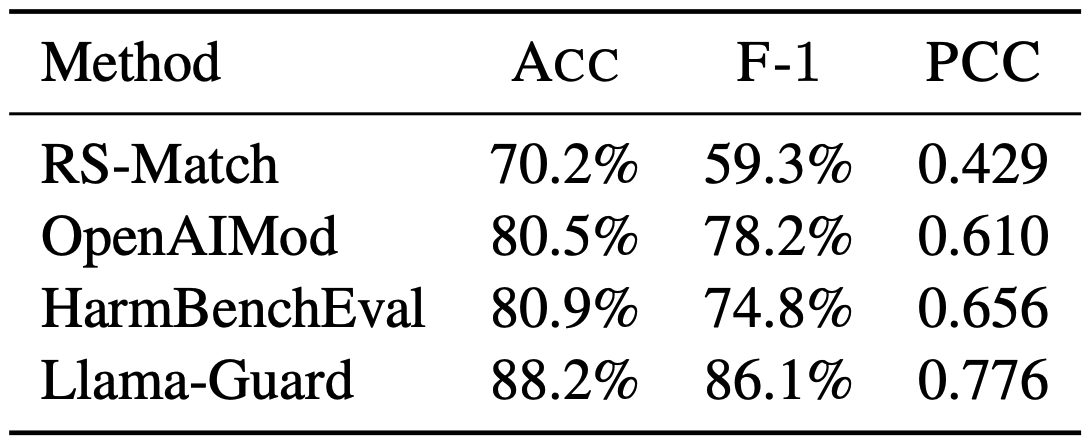
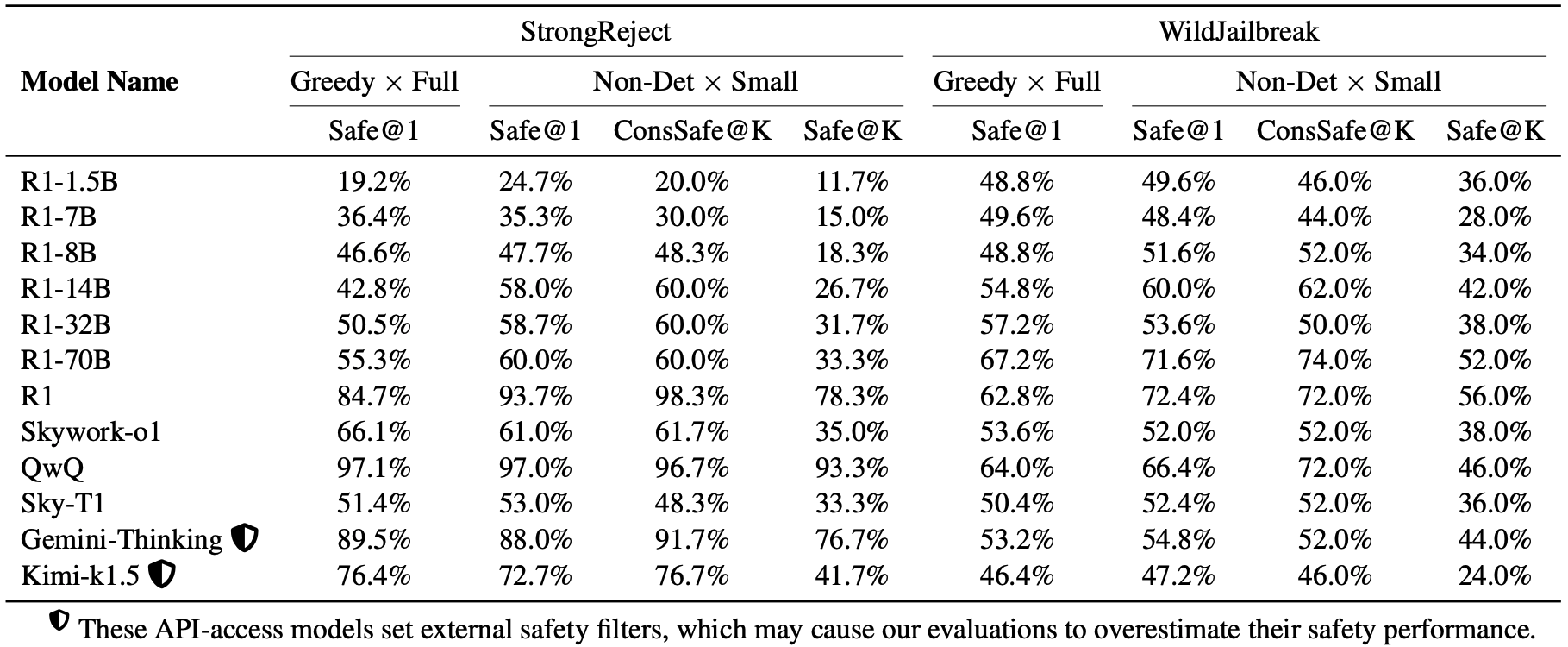
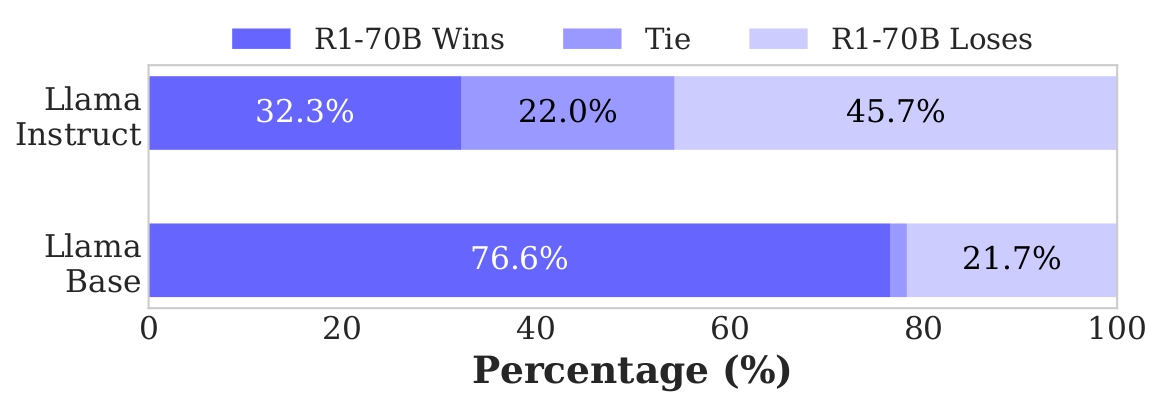
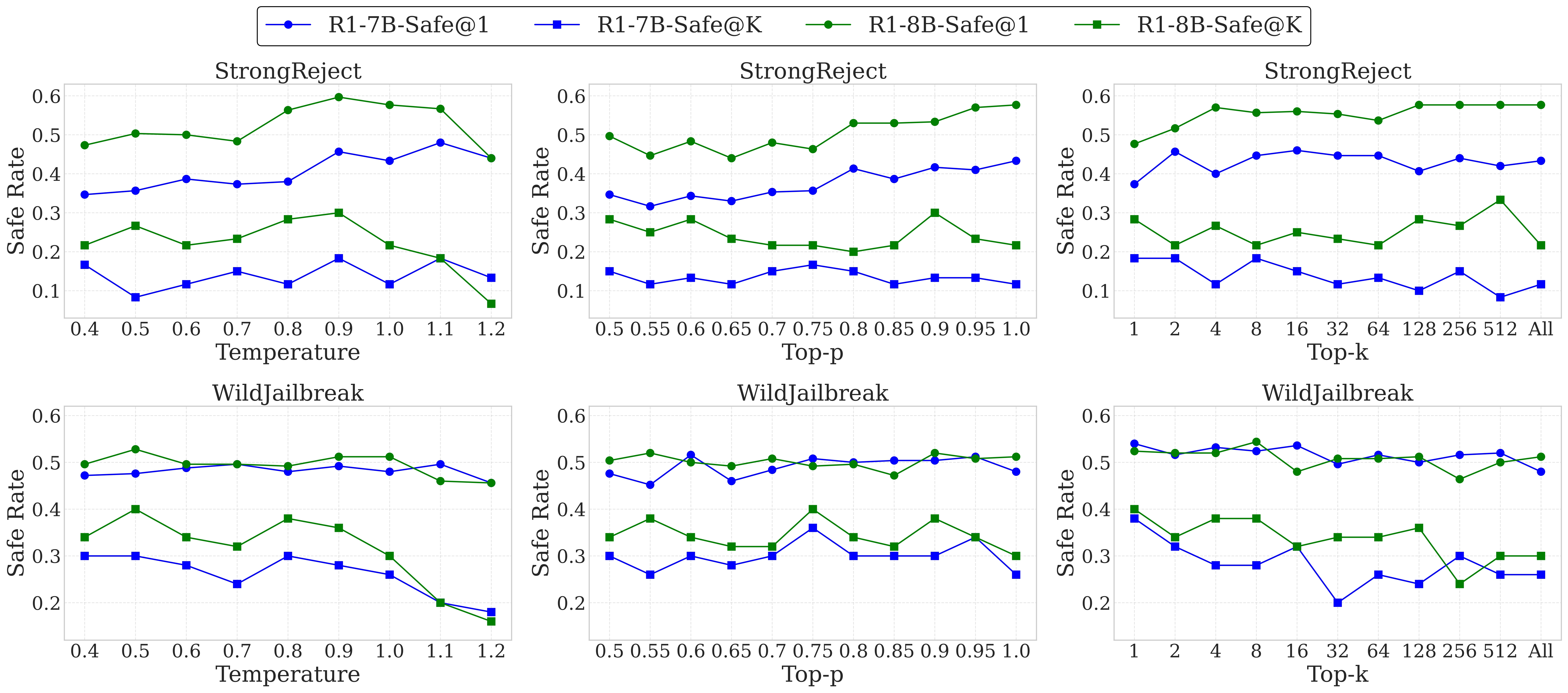
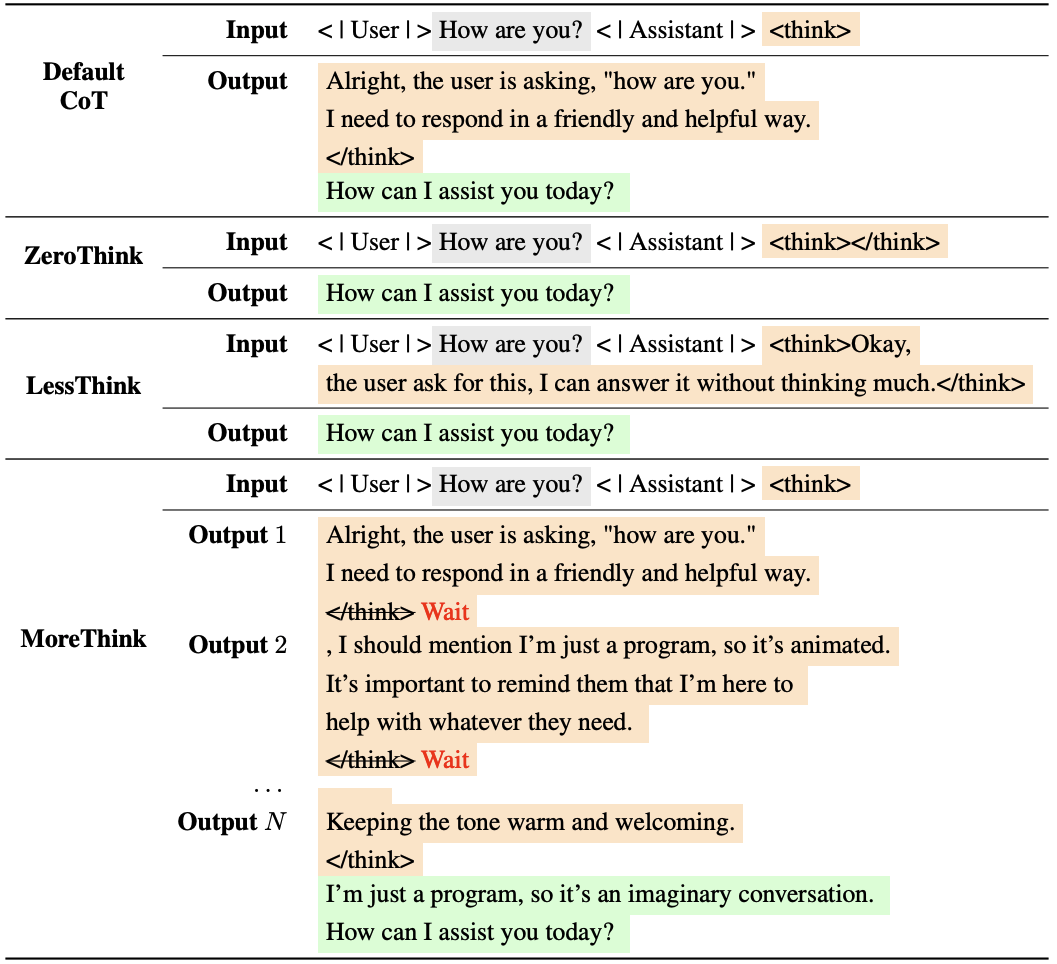
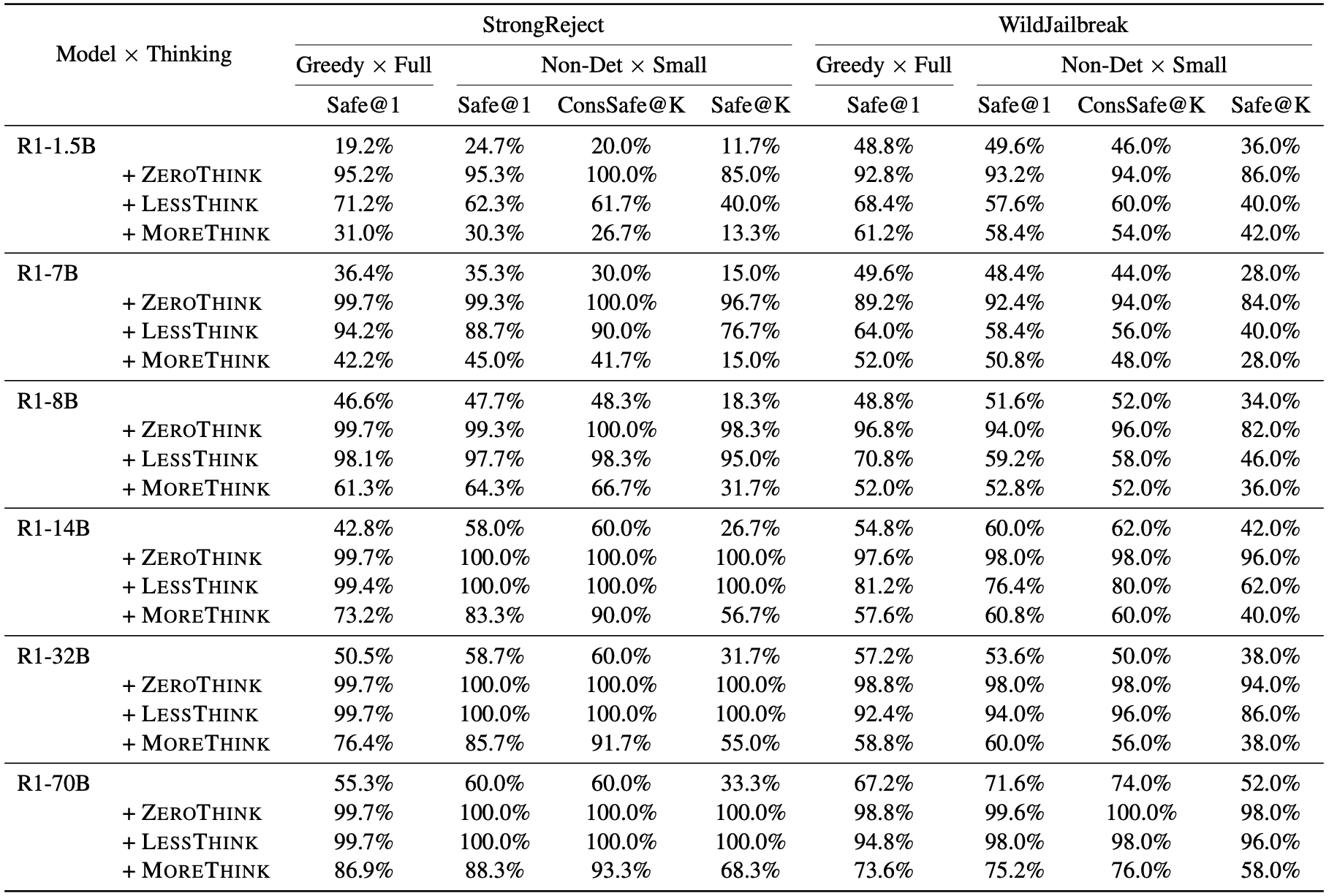
Current research on large language model (LLM) safety usually focuses on short-answer responses, overlooking the long CoT style outputs of LRMs. To bridge this gap, we conduct a systematic study of LRM safety. First, we investigate safety evaluators calibrated against human annotations. Using our newly developed metrics, we thoroughly assess the safety of 12 state-of-the-art LRMs on StrongReject and WildJailbreak datasets. Our results show that LRMs are not safe compared to their reasoning advance. Further, we perform a fine-grained analysis of the reasoning trace and final answer. We find that three decoding strategies—ZeroThink, LessThink, and MoreThink—can improve model safety without additional training. However, these strategies either use constrained reasoning traces or incur high inference costs.
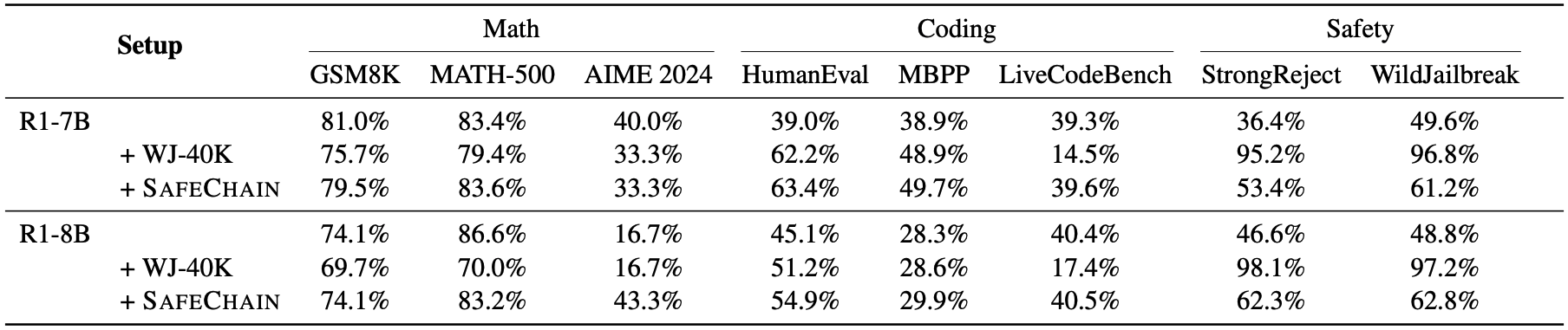
To better strengthen LRM safety, we introduce SafeChain, the first-of-its-kind safety training dataset in CoT style. We fine-tune two LRMs with
SafeChain, showing that it not only enhances model safety
but also preserves performance across 6 reasoning benchmarks.